Een buffet ergens in Nederland. Het zou een schrijdend buffet in het Paleis op de Dam kunnen zijn, maar ook een lopend buffet in de feestruimte van Aeskwadraat. De buffetmeester die speciaal voor deze gelegenheid is aangesteld houdt nogal van orde en komt op het lumineuze idee om de gasten een menu te geven met een gesuggereerde looproute:
Parallelle computerprogramma's proberen een berekening sneller uit te voeren door meerdere processoren gelijktijdig te laten rekenen. Een typische lus in een parallel programma ziet er als volgt uit:
/* Programmatekst voor processor P(i) */
for(j=0; j<p; j++){
get x[j] from P[j];
}
Er zijn p processoren, genummerd
P(0), ... , P(p-1).
Iedere processor haalt bij iedere processor precies één item op,
gebruik makend van
de communicatie-opdracht get.
Eerst haalt hij een kopie van x0 op bij P(0),
daarna x1 bij P(1), etc. De programmeermeester is hier
in dezelfde valkuil getrapt als de buffetmeester:
onbewust heeft hij opstoppingen in
zijn programma ingebouwd.
Een efficiëntere methode zou zijn om iedere processor een verschillende lusvolgorde te geven. Bijvoorbeeld, als p=4, definieer de matrix
![\begin{displaymath}
R=\left[ \begin{array}
{rrrr}
1&2&3&0\\ 3&0&1&2\\ 0&1&2&3\\ 2&3&0&1\end{array} \right] .\end{displaymath}](img2.gif)
Met behulp van deze matrix passen we nu het programma als volgt aan:
/* Programmatekst voor processor P(i) */
for(j=0; j<p; j++){
k=R[i][j];
get x[k] from P[k];
}
Processor P(i) haalt nu in de j-de ronde het item van
processor P(Rij) op. Kijkend naar rij i van R
zien we dat processor P(i) op den duur alle items ophaalt,
zodat hij zijn taak geheel vervult.
Kijkend naar kolom j zien we dat in ronde j alle processoren
verschillende items ophalen, en wel bij verschillende processoren.
Alle opstoppingen zijn dus verdwenen.
Het is uiterst vervelend om bij het programmeren telkens rekening te moeten houden met dit soort verschijnselen. De programmateksten zouden er veel gecompliceerder door worden. Sinds mei 1997 is er een nieuwe standaard voor parallel programmeren, BSPlib [3] genaamd, die dit soort optimalisaties mogelijk maakt zonder de gebruiker ermee lastig te vallen. De eerste implementatie van BSPlib, de Oxford BSP toolset, heeft de vernuftige oplossing gekozen om telkens een ander willekeurig Latijns vierkant te gebruiken als communicatieschema, zie [2]. Dit zorgt voor een gemiddeld goede prestatie, zonder enige netwerkstructuur of communicatiepatroon te bevoordelen of te benadelen.
De gangen van het buffet worden op ons feest duidelijk aangegeven door een gong. De verschillende voorgerechten, hoofdgerechten en nagerechten worden, als het goed is, op verschillende tijdstippen geserveerd. Op een slecht georganiseerd buffet loopt dit alles door elkaar. Koude kalkoen, lauwe sausjes, gesmolten ijs en meer van dat soort onlekkers kunnen door welgeplaatste gongslagen worden voorkomen. Overigens, jarenlange observatie heeft mij geleerd dat buffetgangers het verschil tussen de gangen meestal ontgaat.
Een gongslag heet in de programmeerwereld een globale synchronisatie . De operaties tussen twee gongslagen vormen een superstap . Het Bulk Synchrone Parallelle (BSP) model van Valiant [4] uit 1990 benadrukt het belang van globale synchronisaties en organiseert een parallelle berekening als een opeenvolging van superstappen. De ``bulk'' in BSP staat voor ``grote hoeveelheid". Als buffetwijsheid: schep je bord voldoende vol, anders blijf je voortdurend heen en weer lopen. Als programmeerwijsheid: zorg dat elke superstap voldoende nuttig werk bevat. Dit kan zowel reken- als communicatiewerk zijn. De extra kosten veroorzaakt door de globale synchronisatie mogen de kosten van het nuttige werk niet domineren.
Zonder het concept van de superstap wordt het programmeren (en het eten) een stuk moeilijker. Veelgebruikte communicatiebibliotheken als PVM uit 1990 en MPI uit 1994 zijn gebouwd op paarsgewijze communicatie en synchronisatie, ook wel bekend als het Communicating Sequential Processes (CSP) model van Hoare. Je kunt communicatie hierbij opvatten als handenschudden, of het overhandigen van een bord eten, waarbij beide partijen pas na voltooiing van de transactie door kunnen gaan met hun activiteiten. Er zijn dan geen momenten van globale synchronisatie, en dit maakt het onmogelijk om een bepaalde fase af te zonderen en deze apart te optimaliseren of te analyseren. Tijdsanalyse vergt dan het nauwkeurig onderzoeken van alle paarsgewijze interacties gedurende de totale berekening.
Het is omslachtig als je bij een buffet je bord aan de serveerder zou moeten geven, waarna deze er een stukje kip op deponeert en het bord teruggeeft. Deze tweezijdige operatie zou veel sneller kunnen als de serveerder direct de spijs op de juiste plek op het bord zou doen belanden, zonder interventie van de eter. Deze zou alleen passief moeten toekijken hoe haar bord gevuld wordt. Zo'n eenzijdige operatie is niet alleen efficiënt, maar ook conceptueel eenvoudig.
In modern parallel programmeren worden tweezijdige communicaties, gebaseerd op een paar van gekoppelde send en receive operaties, steeds vaker vervangen door eenzijdige communicaties, die een put of een get operatie gebruiken, maar niet beide tegelijk. Bij de put is de verzender de initiatiefnemer, bij de get is dat de ontvanger. De andere kant doet niets. BSPlib is gebaseerd op eenzijdige communicaties: er is een bsp_put, een bsp_get, en een eenzijdige bsp_send die bedoeld is voor een situatie waar de bestemmingsprocessor wel bekend is maar het precieze bestemmingsadres in die processor niet. In dat geval wordt er een ontvangstbuffer gebruikt, die in de volgende superstap kan worden leeggehaald. (Dit kan, maar het moet niet. Daarom mogen we de operatie toch als eenzijdig beschouwen.) In de buffetsituatie: het bord is bekend, maar de serveerder kan zelf niet beslissen of hij de kip nu links of rechts van de aardappelen zal neerkwakken. Dit kan voorkomen als meerdere serveerders tegelijkertijd, in dezelfde superstap, hun gerecht op hetzelfde bord willen deponeren zonder weet te hebben van andermans precieze intenties. In zo'n geval kunnen de serveerders het beste een extra bord gebruiken, daar in een onderling afgesproken volgorde de spijzen op deponeren, en de eter zelf laten beslissen hoe het voedsel uiteindelijk op zijn bord komt. Dat gebeurt via de bsp_move operatie in de volgende superstap.
Een welbekende situatie treedt op als er toevallig
Engelse gasten aan het buffet
deelnemen. Zij raken met elkaar in gesprek, wisselen beleefdheden uit
terwijl de Nederlanders allang aan hun tweede ronde begonnen
zijn, en besluiten uiteindelijk ook maar aan de maaltijd te beginnen.
Ze lopen al babbelend naar het voedsel en laten elkaar uiteraard voorgaan:
``after you, my dear",
``after you, my dear",
``after you",
``after you", ...
En zo gaat dat de hele avond door, totdat het voedsel
koud is en de Engelsen teleurgesteld en
uitgehongerd afdruipen.
Dit verschijnsel heet deadlock . Onbedoeld komt het
veel voor in programma's gebaseerd op tweezijdige communicatie.
Het drijft programmeurs soms tot wanhoop, want het programma crasht niet,
maar geeft ook geen uitvoer.
Bij eenzijdige communicatie kan deadlock per definitie niet voorkomen.
Wel reiken twee processoren soms naar dezelfde gegevens; het systeem
zorgt er dan voor dat ieder een kopie krijgt.
Als twee processoren een gegeven in dezelfde geheugencel willen zetten
via een put operatie, dan is het onbepaald wie er wint.
Dit zal van de BSP implementatie en de machinearchitectuur afhangen.
Deadlock kan dit echter niet opleveren, hoogstens enig
spannend nondeterminisme.
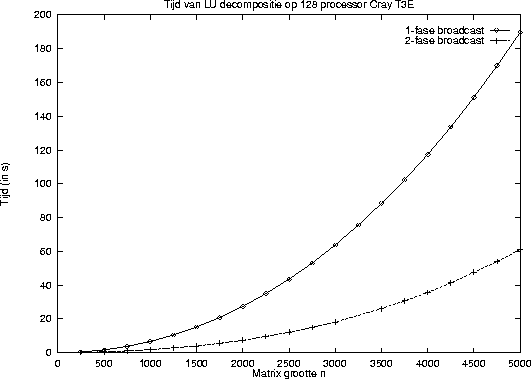
Elk model wordt vroeg of laat geconfronteerd met de realiteitsvraag. In hoeverre kloppen de voorspellingen van het BSP model met de werkelijkheid? Laten we dit eens bekijken aan de hand van de broadcast operatie waarbij iedereen een kopie van een bepaalde boodschap toegezonden krijgt. Iedere buffetgast ontvangt als aandenken een kookboek van 400 pagina's, een bestseller getiteld Koken ná Montignac . Helaas, het geld is op en de gastheer kan geen 100 exemplaren aanschaffen. Hij koopt één exemplaar en besluit in de beste academische traditie een roofdruk te produceren. Hij neemt een abonnement bij een printerette maar bedenkt dat het wel erg lang zou duren als hij zelf alles zou kopiëren. Dit kost immers 40000 kopieeroperaties van een seconde en daarna een gongslag om de gasten te laten weten dat hij klaar is. Dan zijn we echter minstens een werkdag verder. De gastheer besluit op instigatie van de gastvrouw tot een betere oplossing. Hij maakt keurig één kopie van elke pagina van het boek, geeft iedere gast vier pagina's met daarbij de opdracht deze bij een printerette in honderdvoud te kopiëren. Als ieder klaar is gaat de gong en vervolgens verspreidt elke gast zijn of haar kopieën onder alle gasten. Deze leggen de ontvangen pagina's op de juiste volgorde en dan slaat de gong weer. Klaar is Kees. Dit proces heet een twee-fase broadcast . Volgens ons model kost de eerste fase 400 operaties en een gongslag; de tweede fase kost hetzelfde. In BSP taal: de twee-fase broadcast kost in totaal 800g+2l (Veel minder dan de één-fase broadcast die 40000g+l zou kosten.)
Om de voorspellingen van het BSP model te testen heb ik
een lineair stelsel van vergelijkingen opgelost op een supercomputer,
de Cray T3E van het
Commissariat à l'Énergie
Atomique in Grenoble.
De BSP parameters van deze machine zijn:
aantal processoren p=128;
rekensnelheid per processor s=47 Mflop/s (d.w.z. miljoen flops, floating
point berekeningen, per seconde);
communicatiekosten per data woord g=123 (in tijdseenheden van een flop);
synchronisatiekosten l=7861 tijdseenheden.
Plaatje 1 laat de tijd zien voor de hoofdmoot van
de berekening, een LU decompositie van een n bij n
matrix, met n
oplopend tot 5000.
Voor meer details, zie [1].
De berekening met de twee-fase broadcast wint duidelijk
(ondanks dat er juist meer gegevens worden verstuurd).
Dit kan uitsluitend worden verklaard
uit de betere balans in het communicatiewerk.
Conclusie: spreiding van werk en verantwoordelijkheid loont!
Je hoeft geen peperdure supercomputer te kopen om met BSPlib te kunnen experimenteren. Wij gebruiken BSPlib in de computerpractica van het vak Parallelle Algoritmen voor Supercomputers, dat onderdeel is van het derde jaar van de opleiding Computational Science. De machines waar we BSPlib op draaien zijn een Cray T3E met 64 processoren van de TU Delft, en een cluster van acht werkstations in een computerleerzaal van het Mathematisch Instituut van de UU; de werkstations zijn onderling verbonden via een Ethernet. De cluster versie is gebaseerd op TCP/IP. Deze implementatie heeft een aantal interessante eigenschappen waaronder toeritdosering: binnen een communicatiesuperstap worden datapakketjes in optimaal tempo losgelaten op het Ethernet, zodat botsingen zoveel mogelijk worden voorkomen. (De prestatie van het Ethernet gaat juist achteruit als er te veel pakketjes tegelijkertijd verstuurd worden.) Dit optimaliseren is mogelijk omdat de communicatie geïsoleerd is in superstappen. Soms gebruiken we een BSPlib simulator. Bovendien hebben veel Computational Science studenten thuis op hun eigen PC de LINUX versie van BSPlib geïnstalleerd.
Tot slot, BSPlib kun je gebruiken om programma's te parallelliseren en daarna, zonder een regel te veranderen, te draaien op allerlei computers. BSPlib is te gebruiken in alle situaties waar je een homogene parallelle computer hebt. Gebruik BSPlib echter niet als de processoren onderling verschillen van architectuur. Daarvoor hebben MPI en PVM betere mogelijkheden. Volg de oude wijsheid dat je in hotels niet eet, omdat je in restaurants niet slaapt.